Эта история и не про дизайн, и не про код. Она про то, что всегда (наверное) можно придумать, как сделать дёшево и просто.
«Самый простой способ обзавестись нужными инструментами — оказаться перед необходимостью двигаться быстрее или в более сложной среде». Людвиг Б.
Я коллекционирую монеты с 8 лет: кто-то подарил мне два литовских цента, и понеслось. Всё это время я с переменным пристрастием относился к коллекционированию, но в последние несколько лет тренд выровнялся в постоянное пополнение коллекции небольшими порциями 1-2 раза в месяц.
Когда количество монет перевалило за пять сотен, я придумал и сделал Coin Index (о процессе создания), который навёл порядок в коллекции, позволил не держать в голове её статус и обозначил цели. С тех пор коллекция перешагнула за 1 200 экземпляров: «закрыл» очень много распространённых монет, начал налегать на редкие. И всё это происходит так: иду на сайт аукциона → ищу продавца с большим количеством лотов → перебираю все лоты. Занятие тупое, но медитативное. (У каждого из нас свои способы провести вечер с выключенным мозгом после трудного дня.)
Так вот. Раньше перебор одной страны продавца могло доходить до 15 минут. А стран много. Потом я добавил на страницу Coin Index поле поиска, которое принимает на вход два числа типа «5 45» и оставляет на страницы все «пятёрки» 1945 года. Время перебора сократилось в пару раз. Работа мозга на этом этапе сократилась раз в десять.
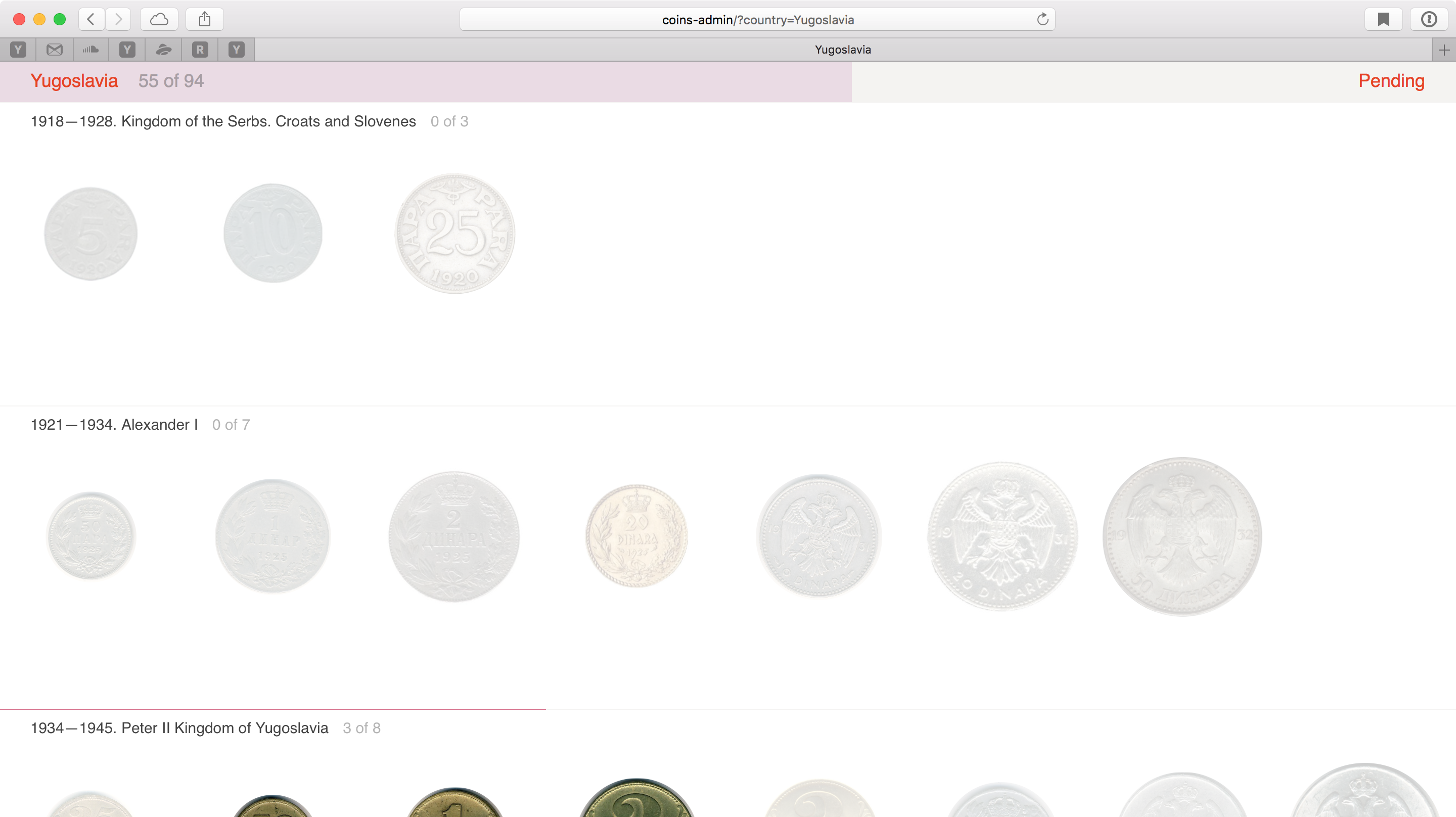
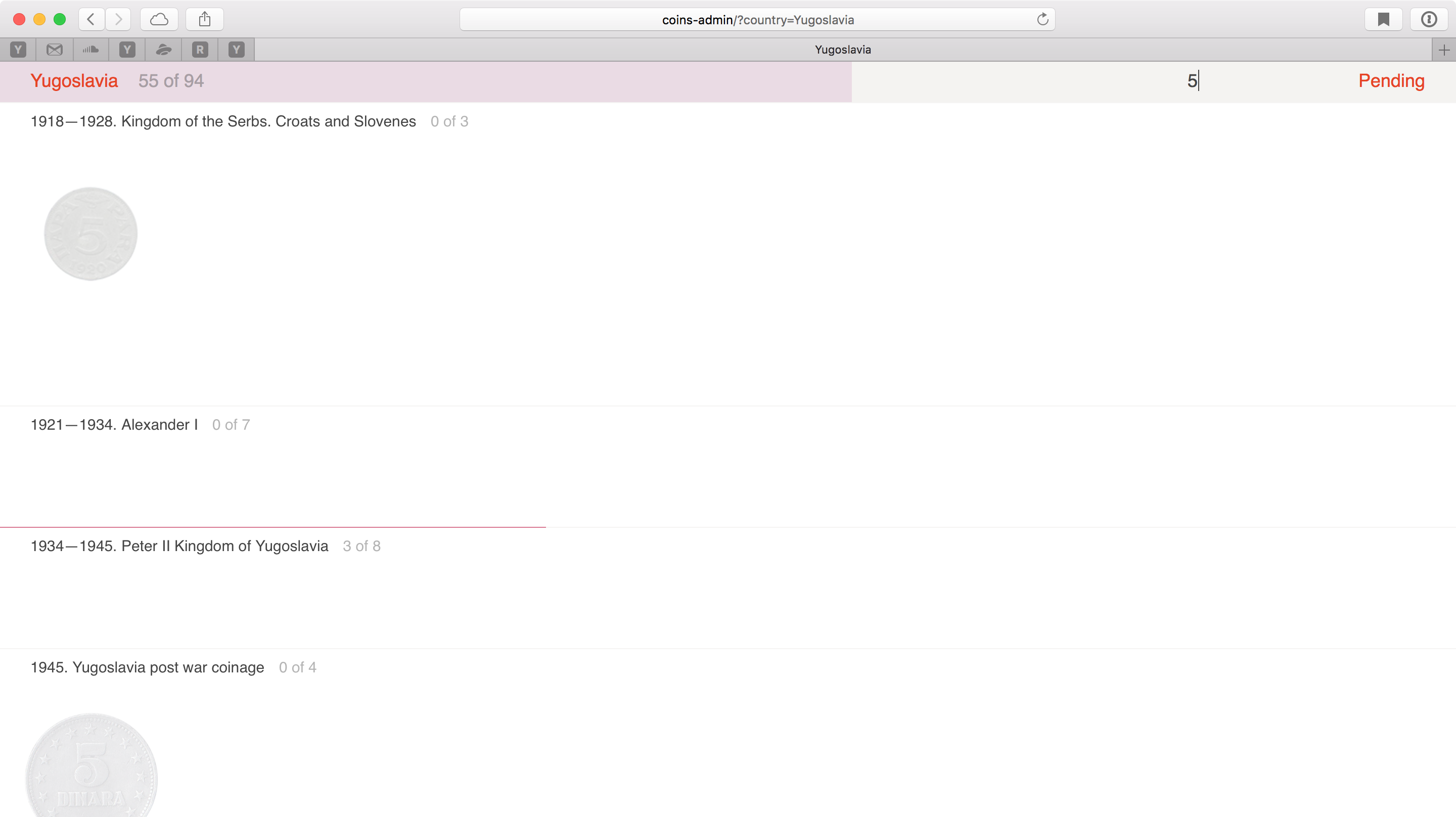
Ввожу «5» — скрылось всё, где номинал не равен 5
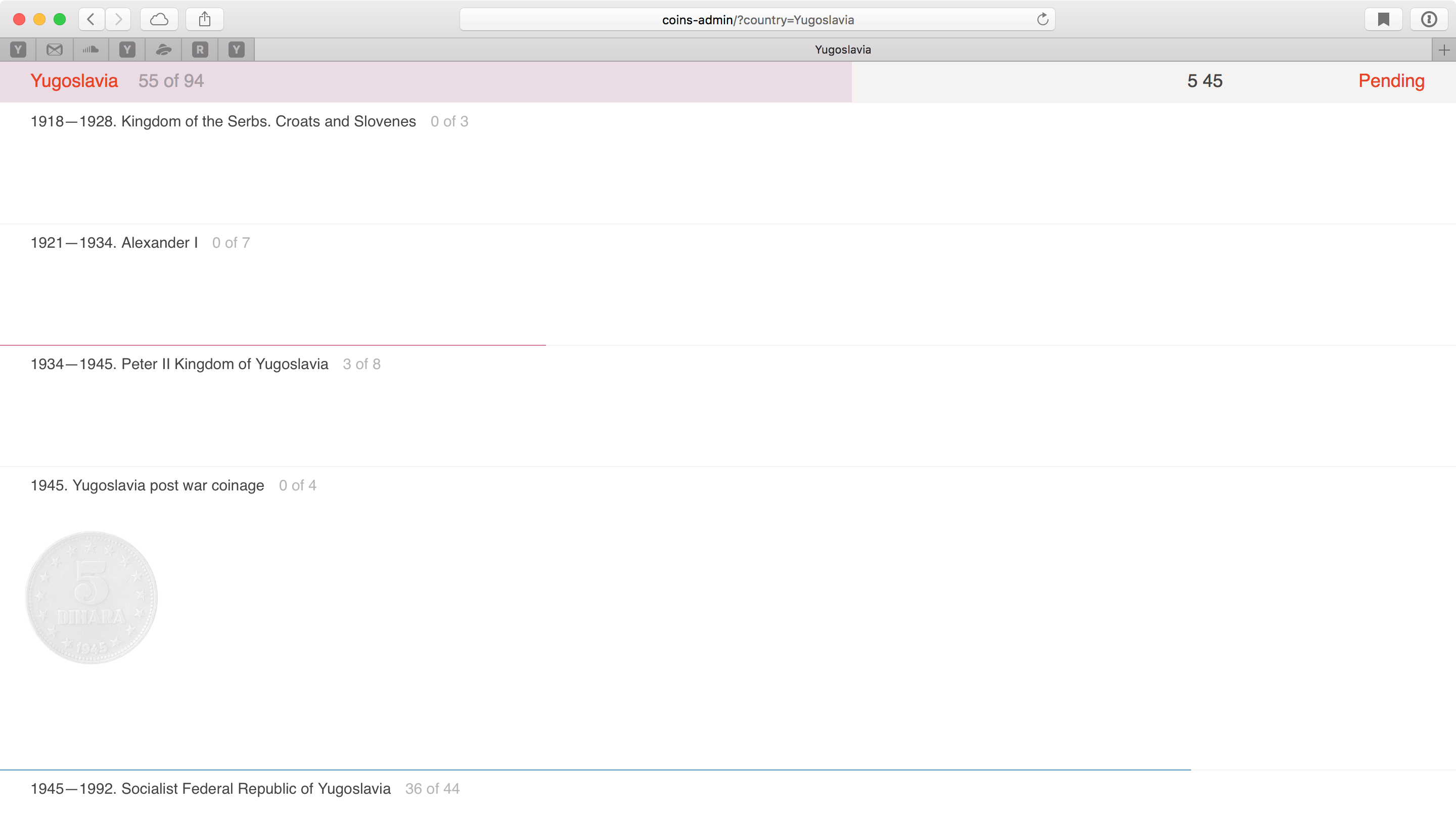
Добавляю «45» — остались только монеты, которые могли быть отчеканены в 1945 году.
Ладно, конечно же меня всё это время бесило такое занятие: зачем делать работу руками, если её за меня может делать скрипт. Но это же надо написать такой скрипт, который сможет по-умному парсить аукцион, понимать страну, год, номинал, денежную единицу из названия лота. А у каждого продавца название лота — это какой-то заголовок, написанный от балды.
Короче, без нейронных сетей и машинного обучения не обойтись, придётся и дальше перебирать руками.
Но что, если отойти от идеи нахождения недостающих монет к идее отсекания имеющихся. Даже самая грубая попытка понимания номинала и года поможет отсечь левак.
У большинства продавцов название лота описано как «Бла-бла-бла 1 динар бла-бла-бла 1953 бла-бла-бла Словения». Самая примитивная регулярка достаёт номинал и год. Страну можно вытянуть из GET-параметров в URL. Таким образом покроется большинство лотов. Главное — с чего-то начать. Кто его знает: может через год я придумаю супер-регулярку, которая покроет ещё больше кейсов. Или продам коллекцию.
Для меня очень важно даже в самом простом проекте набросать интерфейс хотя бы на листике. Даже если это интерфейс из одного поля и выдачи. Эскиз — это не от того, что времени много. Наоборот: эскиз для экономии времени. Код всегда будет дороже эскиза. Не представляю, как можно открывать редактор кода и сразу писать HTML и CSS.
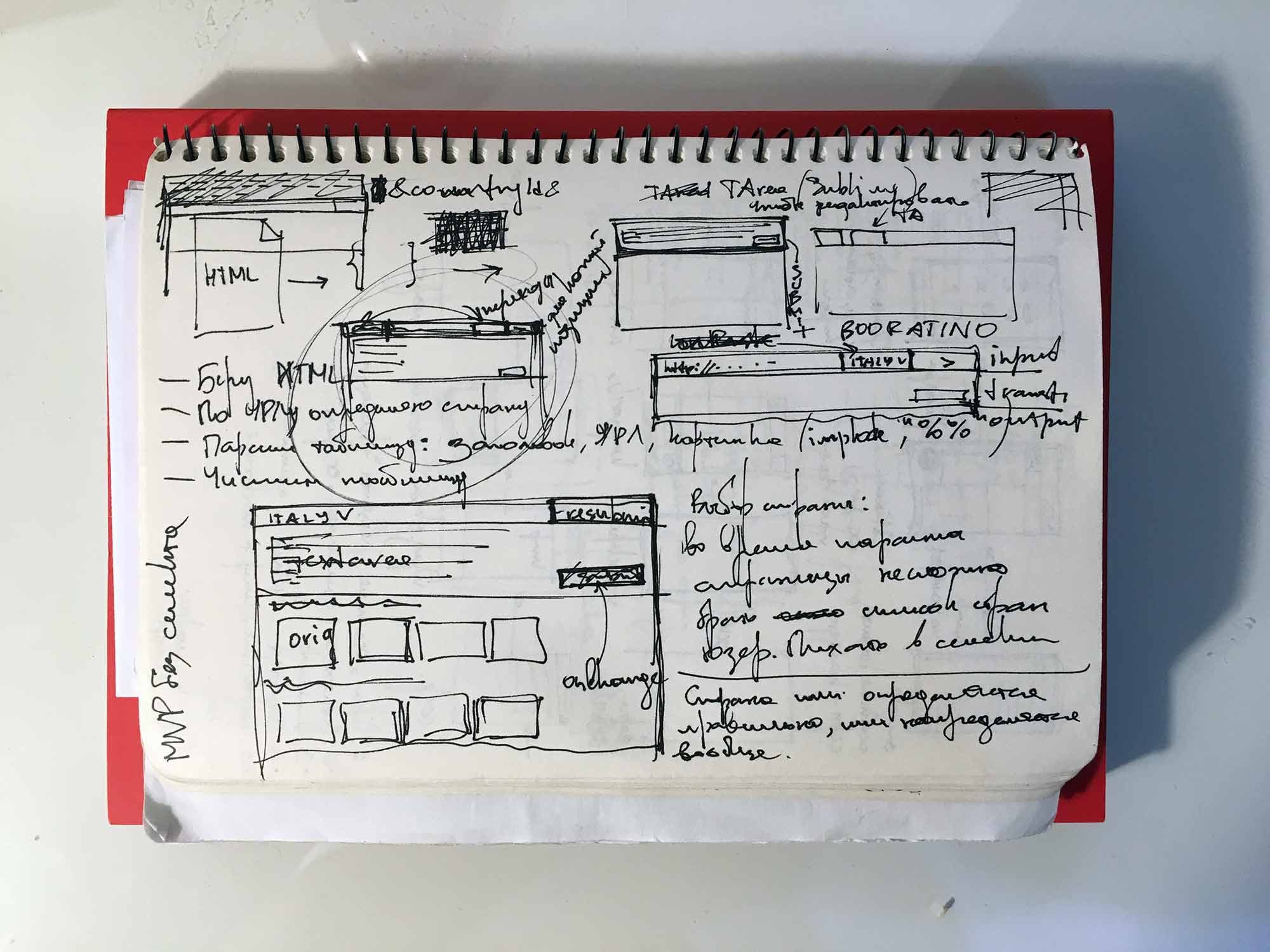
Эскиз за 40 секунд.
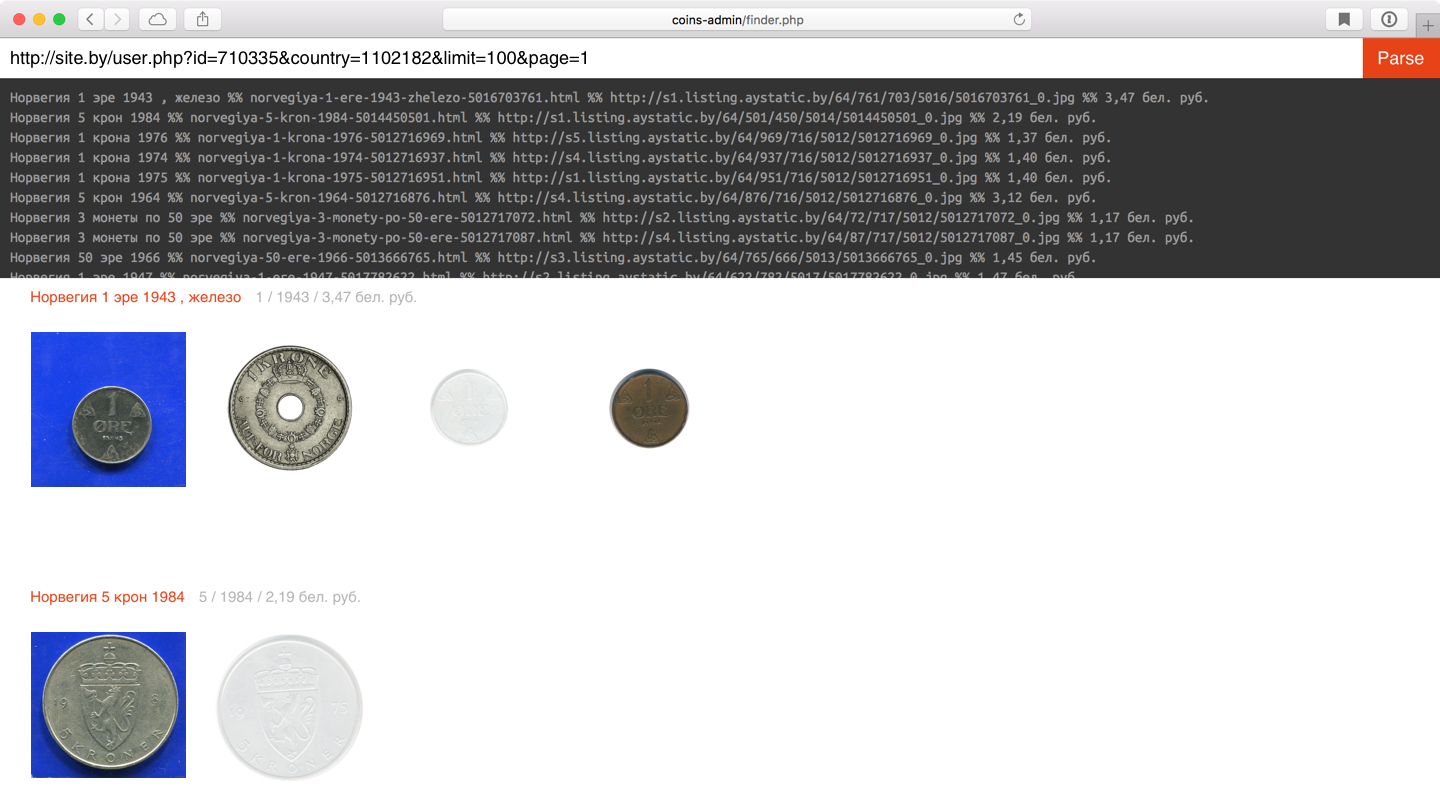
Работающий прототип за столько же времени. Первая картинка в ряду — фотография лота. В заголовках вывожу то, как регулярка поняла номинал и год.
В процессе зарисовок пришла идея, как можно просто научиться понимать «креативные» заголовки, которые выбиваются из общей схемы. Что если делать так: выводим напаршенный массив в текстовую область → закидываем в Sublime Text → Мультикурсором убираем левак → отправляем обратно. Учитывая, что это стоит 0 рублей 0 копеек и нужно очень редко. Добавляю эту идею в проект.
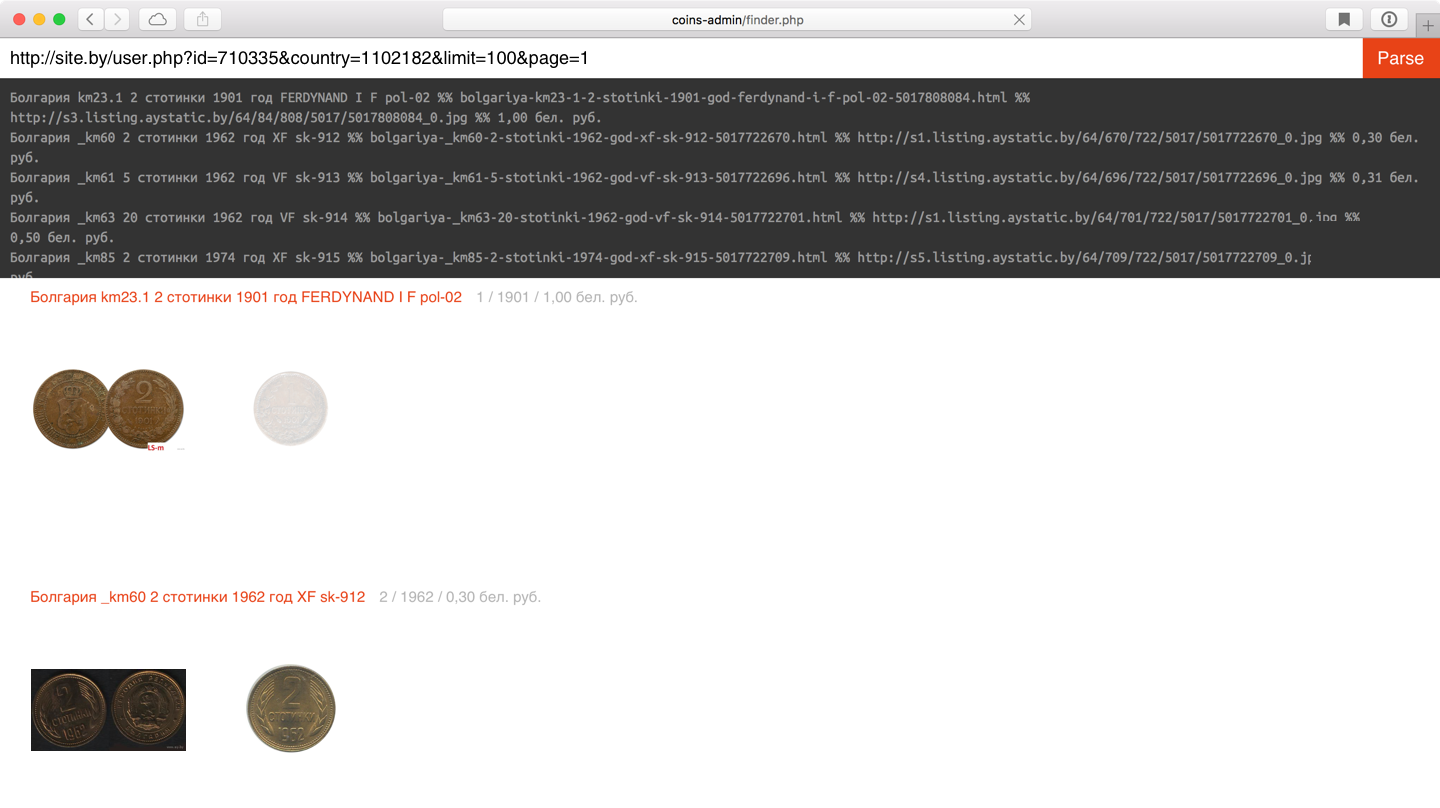
Пример, когда заголовок лота парсится не по привычной схеме. В первом ряду вместо 2 стотинок он видит 1 стотинку. Для таких кейсов можно чистить от ненужных вещей промежуточный массив в текстовом редакторе.
Всё! Примитивная штука сэкономит мне кучу часов времени и поможет прокачать коллекцию.
Невероятное ощущение: всё в ноутисах, криты сыплются, стилей местами нет, всё работает на говнокоде. Но эта штука тебе выдаёт монеты, которых нет в коллекции за полсекунды, а не за 5-10 минут, как если бы я проверял это вручную. Восторг! Вечером придумал → в 4 ночи делаю первый заказ, заодно нахожу на реальных данных эдж-кейсы, которые и не придумал бы.
Наверное, парсить сайт — это плохо. Я никогда не слышал, чтобы за парсинг сайта хвалили. Но если я паршу сайт, чтобы научиться быстрее и больше давать ему денег — это точно плохо? Вообще, когда-нибудь я выучу JavaScript и напишу букмарклет, который будет делать то же, но с выводом в консоль, например.
Очевидно, что от автоматизации оффлайн-хобби может потеряться кайф. Но прямо сейчас нащупан баланс. Есть азарт, коллекция растёт, тратится адекватное количество времени.
3 300 — примерно столько монет было в регулярной чеканке в Европе с 1900 года.
Вот, например, Чехословакия. В секции «1954-1993 Circulation» очень много очень похожих монет, которые у нумизматов разными из-за микропризнаков. Проверять каждый экземпляр вручную — можно с ума сойти. Я вообще не представляю, как можно собрать коллекцию из 3 300 монет без автоматизации.